ue4 draw line in 3d space


Functioning
Operation
guide
guide
Unreal Engine is a leading evolution environment for games, pattern visualizations, cinematics, and more. During evolution with Unreal Engine, as with any real-time application development, it is of import to contour your application to ensure performance requirements are beingness met.
This guide is intended to provide practical advice for profiling and optimizing with Unreal Engine. This current version of the performance guide focuses on profiling and optimizing GPU performance.
There is also information on using FidelityFX Super Resolution with Unreal Engine 4.

The profiling section begins with great advice before your profiling fifty-fifty starts, so goes on to cover topics including repeatable profiling, reducing noise, and determining CPU or GPU-jump.
The Radeon™ GPU Profiler (RGP) is our powerful profiling tool, which yous tin utilize together with Unreal Engine. This department introduces RGP, explains how to utilize it with UE4, and uses an example of 1 of our optimization patches for profiling.
There are several congenital-in profiling tools in UE4 which can be used as a supplement to UE4. This section introduces these tools, and highlights some useful and relevant features.
Larn some valuable general communication for optimizing geometry, draw calls, and GPU execution – which includes some of the born tools and workflows. Find out about upscaling, including using FidelityFX Super Resolution with Unreal Engine.
At AMD, nosotros maintain multiple teams with the primary focus of evaluating the operation of specific game titles or game engines on AMD hardware. These teams often use many of the methodologies presented here while evaluating UE4 products. This last, all-encompassing department takes a guided look into the progression of some of those efforts.
Detect more of our Unreal Engine content here on GPUOpen!
Profiling in Unreal Engine 4
Reduce CPU overhead when profiling
The first question when profiling in UE4 is what build configuration should be used. When profiling the GPU, you want CPU performance to be fast enough to stay out of the mode during profiling. Debug builds should be avoided for profiling, of class, because the engine code is non compiled with optimization enabled.
Be enlightened that Development builds take higher CPU overhead than Test or Aircraft. Still, it can be convenient to contour Development builds. To reduce CPU overhead in Development builds, you should plow off any unnecessary processing on the CPU side and avoid profiling in the editor. The editor can exist made to run as the game using the -game command-line argument. The following command line shows an instance of using -game and disabling CPU work that is not needed for profiling.
UE4Editor.exe ShooterGame -game -nosound -noailogging -noverifygc
Consider using test builds when profiling
Test builds take lower overhead than Evolution, while still providing some developer functionality. Consider enabling STATS for Test builds in the engine's Build.h file, so that UE4's live GPU profiler ( stat GPU ) is available. Similarly, consider enabling ALLOW_PROFILEGPU_IN_TEST , so that ProfileGPU is available. More than details will exist given on stat GPU and ProfileGPU in the Built-In Profiling Tools section.
Exam builds of a stand-alone executable crave cooked content. If you need to iterate while profiling simply want the lower CPU overhead of a Test build, consider using "cook on the wing" (COTF). For case, shader iteration is possible with COTF Exam builds.
Perform terminal checks earlier profiling
Now that your build is gear up for profiling, you should sanity bank check a few things before getting started. First, ensure Frame Rate Smoothing is disabled. It is disabled by default starting in UE4.24, but information technology is good to double check. In the editor, y'all can check in Edit->Project Settings…->Engine –>General Settings->Framerate every bit shown below:
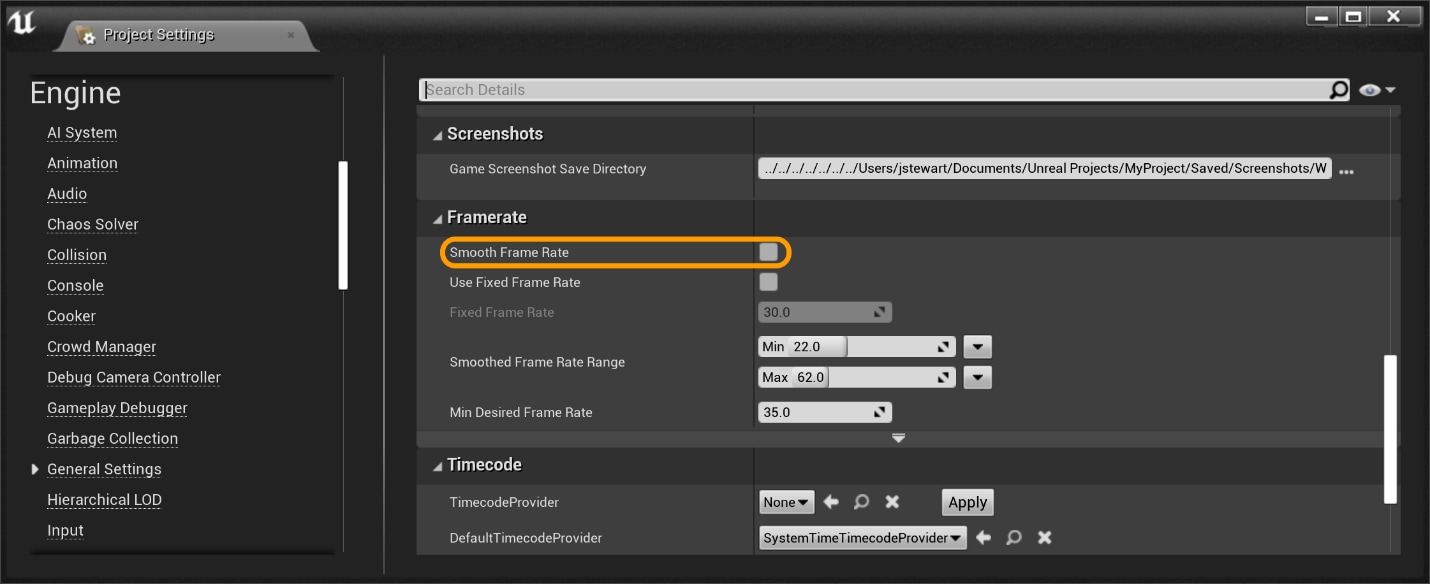
Alternatively, you can ensure bSmoothFrameRate is set to false everywhere it appears in Engine\Config\BaseEngine.ini and your project's DefaultEngine.ini . You can also add bForceDisableFrameRateSmoothing=true to the [/Script/Engine.Engine] section of your projection's DefaultEngine.ini .
Next, turn off VSync. Once style to exercise this is with the -novsync control-line parameter. Adding this to our previous example gives the post-obit:
UE4Editor.exe ShooterGame -game -nosound -noailogging -noverifygc -novsync Lastly, run your build and verify your resolution in the log file. Resolution is, of course, one very important factor in GPU performance, and information technology is worth verifying that it is what you expect. Open the log file for your build and look for a line like the following:
LogRenderer: Reallocating scene render targets to back up 2560x1440
Repeatable profiling
This section contains tips for getting consistent results when profiling, so that yous can better determine if a potential optimization actually improved performance.
Profiling from a single location
One fashion to profile is by going to the same location in your level.
A Player First actor tin can be used to spawn directly to a specific location upon launch. This tin exist dragged into the scene through the editor.
If you lot have no mode to change the scene in editor mode, or would like to teleport while in-game, then you tin use the UCheatManager BugIt tools. Note: BugIt tools are only available in not-aircraft builds.
To teleport using BugIt:
- First open up a console window. In-editor this is accessible via Window->Developer Tools->Output Log. If you are in-game, use console control
showlog. - Type
BugItinto the panel. The kickoff line in the output string should look similar this:BugItGo x y z a b c. - This
BugItGocontrol can be pasted into the panel to teleport to the electric current location from anywhere.
Reducing noise in profiling results
When attempting to optimize the execution time of a workload, we need to be able to reliably measure the fourth dimension a certain workload takes. These measurements should have every bit little racket as possible. Otherwise, we cannot tell whether information technology ran faster because of our optimization or because some random number generator decided to spawn fewer particles (for example).
UE4 has some born functionality to help with this. The -criterion command-line argument causes UE4 to automatically change certain settings to be more than friendly to profiling. The -deterministic statement causes the engine to use a fixed timestep and a stock-still random seed. You can and then apply -fps to set the fixed timestep and -benchmarkseconds to have the engine automatically shut downwardly after a fixed number of timesteps.
Below is an instance of using these arguments with a Exam build of the Infiltrator demo:
UE4Game-Win64-Test.exe "..\..\..\InfiltratorDemo\InfiltratorDemo.uproject" -nosound -noailogging -noverifygc -novsync -benchmark -benchmarkseconds=211 -fps=threescore -deterministic In the above instance, benchmarkseconds is not wall-clock seconds (unless every frame of the demo runs at exactly sixty fps). Rather, it runs 211×60=12,660 frames using a fixed timestep of one/60=16.67 milliseconds. This ways that, if you take your project set up to run a photographic camera flythrough on startup, information technology will advance through the flythrough using fixed timesteps and a fixed random seed. Information technology will then shutdown automatically after a stock-still number of frames. This can be useful in gathering repeatable average frame time data for your level.
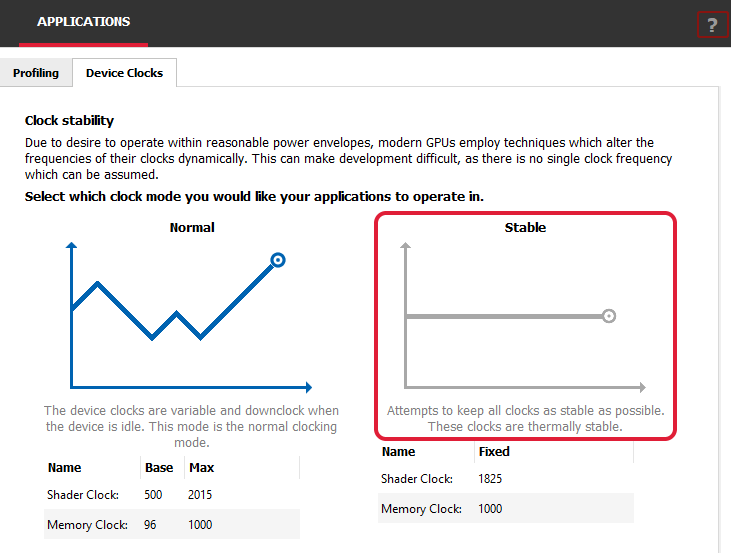
Another technique for helping reduce dissonance in profile results is to run with stock-still clocks. About GPUs take a default power direction system that switches to a lower clock frequency when idle to save power. But this trades lower power consumption for operation and can introduce noise in our benchmarks, as the clocks may not scale the same style between runs of our awarding. Yous may fix the clocks on your GPU to reduce this variance. Many third-party tools exist, just the Radeon Developer Panel that comes with the Radeon GPU Profiler has a Device Clocks tab nether Applications which can be used to set a stable clock on AMD RDNA™ GPUs, as shown below:
Getting back to reducing variability in UE4, yous may find that some things exercise not obey the fixed random seed from the -deterministic control-line argument. This was the case for some particles in the Infiltrator demo. These particles were causing a noticeable amount of noise in our benchmarks.
The solution to reducing particle dissonance is to make the Random Number Generators used a stock-still seed. This is how you lot make the particles deterministic in just 2 clicks:
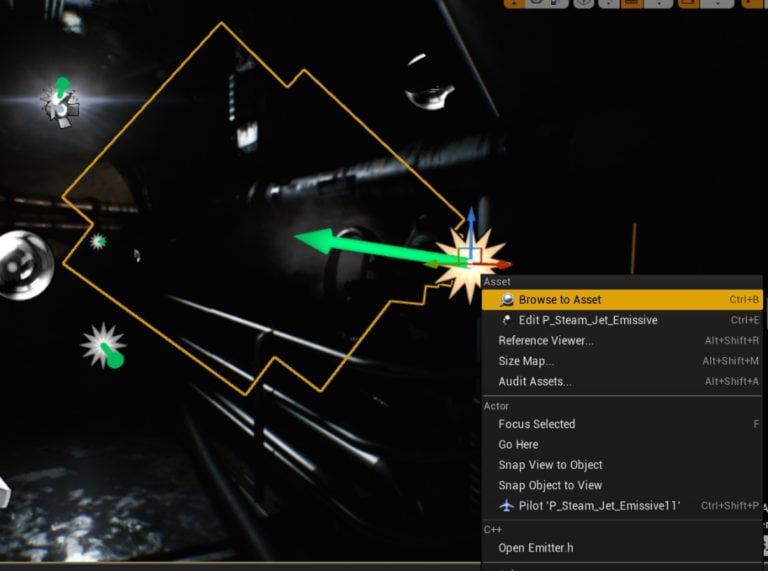
1- Right click on the emitter of particles then click on "Browse to Nugget"
2- Once the emitter nugget gets selected in the Content Browser, right click on it and select "Convert To Seeded"
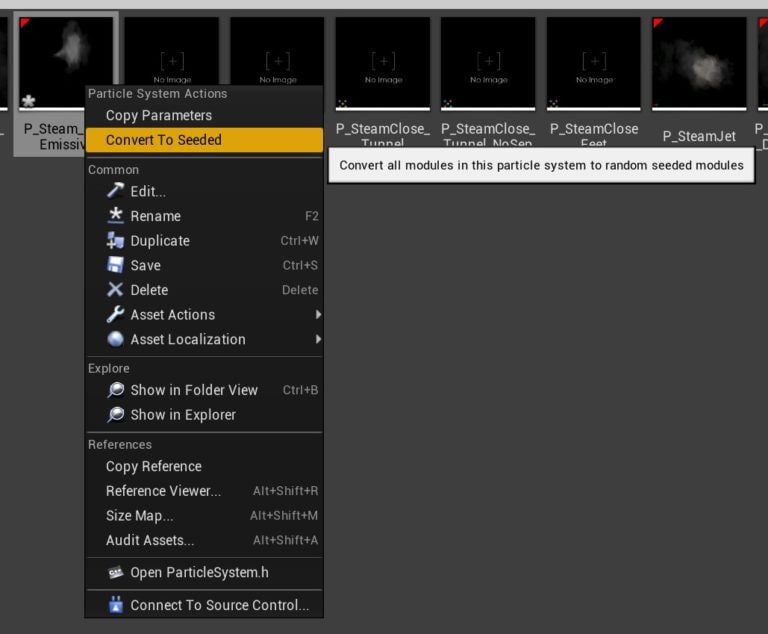
That's it! You lot can also select all your emitters in the Content Browser and convert them all at in one case. Once that has been done the racket volition exist much reduced and it should exist very easy to evaluate your optimizations.
Note: If you lot are using Niagara particles, look for "Deterministic Random Number Generation in Niagara" in the official UE4.22 release page: https://www.unrealengine.com/en-United states/web log/unreal-engine-4-22-released
Consider making your own test scene
Optimizing an effect requires trying many experiments, and every iteration takes time. We need to rebuild the game, cook the content, etc. UE4 features like melt on the fly (COTF) can assistance with this. But it tin also be useful to isolate the upshot or technique you are optimizing into a small application.
If only we could generate such an app hands! Fortunately, Unreal comes with a feature called Drift for that. It extracts a certain asset with all its dependencies and volition import it in whatever other project. In this example, for the sake of creating a minor app, we would migrate the outcome into an empty project.
Official documentation on migrating assets: https://docs.unrealengine.com/en-The states/Engine/Content/Browser/UserGuide/Migrate/index.html
CPU-bound or GPU-bound?
When getting started with performance profiling in UE4, information technology is important to know where the primary functioning bottlenecks are when running on the target platform. Depending on whether the clogging lies on the CPU or GPU, we may go in orthogonal directions with our performance assay.
Afterwards taking a performance capture with the Radeon Developer Panel (RDP), these details are available in the Radeon GPU Profiler (RGP) from the Overview->Frame Summary view.
The following shows an extreme CPU-spring example, created past calculation CPU busy piece of work to UE4, followed by a GPU-bound scene.
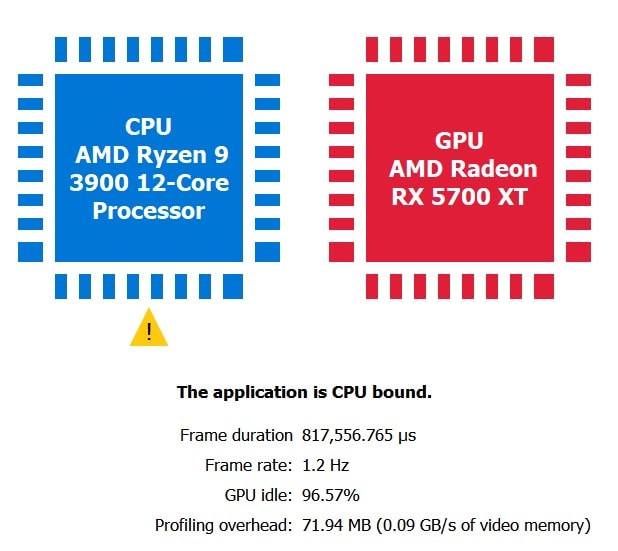
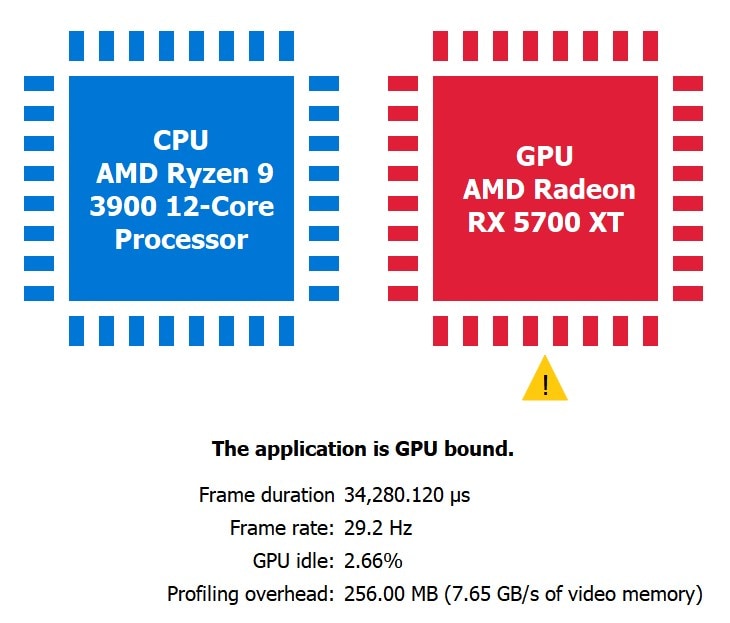
A good sanity test to check if the application is indeed CPU bound is to calibration up the return resolution. For example, if the GPU workload is increased past setting r.ScreenPercentage from 100 to 150 and RGP shows the aforementioned CPU bound result as before, that is a strong indication the app is thoroughly CPU bound.
One time nosotros determine if we are GPU-bound or CPU-leap, we may decide to diagnose farther with RGP (if we are GPU-bound) or switch to other tools like AMD μProf (if we are CPU-bound). As mentioned earlier, this version of the guide is focused on the GPU, then we volition now hash out how to decide where the GPU's fourth dimension is being spent.
Using RGP
The Radeon™ GPU Profiler (RGP) is a very useful tool for profiling on RDNA GPUs. To capture with RGP using UE4, we must run UE4 on either the D3D12 RHI or the Vulkan RHI. This guide will use D3D12 for its examples. You tin invoke the D3D12 RHI either past running the UE4 executable with the -d3d12 command-line argument or past changing the default RHI in the editor: Edit->Projection Settings…->Platforms->Windows->Default RHI to DirectX 12.
Before capturing with RGP, uncomment the following line in ConsoleVariables.ini : D3D12.EmitRgpFrameMarkers=ane . This ensures that whatever UE4 code wrapped in a SCOPED_DRAW_EVENT macro appears as a useful mark in RGP.
Notation: if you are using a Test build, either ALLOW_CHEAT_CVARS_IN_TEST in Build.h then that ConsoleVariables.ini volition be used in Exam builds or add a [ConsoleVariables] section to your project'southward DefaultEngine.ini :
[ConsoleVariables] D3D12.EmitRgpFrameMarkers=ane
RGP and UE4 example
This department uses one of our UE4 optimization patches on GPUOpen to demonstrate using RGP to profile. This example reduces frame time by 0.2ms (measured on Radeon 5700XT at 4Kone). 0.2ms may not seem like much at first, but if you are targeting 60fps for your game, 0.2ms is roughly 1% of your lx-Hz frame budget.
If you take the patch and want to reproduce the results in this section, first use the console to disable the optimization: r.PostProcess.HistogramReduce.UseCS 0
Subsequently taking a functioning capture with RDP, these details are available in RGP from the Events->Event Timing view. If you are emitting RGP perf markers, you tin can apace navigate to the marker that we are investigating by searching for " PostProcessHistogramReduce ".

Nosotros tin can encounter that the DrawIndexedInstanced() telephone call takes 211us to complete. We tin practise better!
To inspect the details of the pixel shader running on the GPU, right-click on the draw call, select "View in Pipeline State" and click on PS in the pipeline.
The Information tab shows that our pixel shader is only running 1 wavefront and but taking up 32 threads of that wavefront. On GCN GPUs and above, this kind of GPU workload will execute in 'partial waves' which ways the GPU is being underutilized.
The ISA tab will give us the exact shader instructions that are executed on GPU hardware as well as VGPR/SGPR occupancy. The ISA view is also useful for other optimizations like scalarization which are not covered hither (https://flashypixels.wordpress.com/2018/xi/10/intro-to-gpu-scalarization-role-1/)
Viewing the HLSL source ( PostProcessHistogramReduce.usf ) for this shader shows that there is a lengthy loop that we need to parallelize if nosotros want to maximize the GPU hardware and eliminate any fractional waves. We did this by switching to a compute shader and leveraging LDS (local data store/groupshared retention) – a hardware feature available on modern GPUs which back up Shader Model 5.
Adjacent, we can enable our optimization to see the performance impact: r.PostProcess.HistogramReduce.UseCS 1
After taking another performance capture with RDP and going back to the Event Timings view in RGP:

The time taken for the acceleration is 7us – for a whopping 96% performance uplift! The majority of the time taken is now in the barrier which is unavoidable every bit our PostProcessHistogramReduce pass has a information dependency on the prior PostProcessHistogram pass.
The reason for this performance gain is executing shorter loops, leveraging LDS for reduction and using load instead of sample (paradigm loads get through a fast path on RDNA). Going to the ISA view shows us the new LDS work happening within ds_read* and ds_write* instructions.
ane – Organisation Configuration: Ryzen 9 3900, 32GB DDR4-3200, Windows ten, Radeon Software Adrenalin 2022 Edition 20.2.2, 3840×2160 resolution
Congenital-in profiling tools
This department covers the built-in UE4 profiling tools. These tin can serve equally a supplement to profiling with RGP.
UE4 stat commands
A list of all stat commands is officially documented hither: https://docs.unrealengine.com/en-US/Engine/Operation/StatCommands/index.html
The nigh important commands pruned from the above listing:
-
stat fps: Unobtrusive view of frames per 2nd (FPS) and ms per frame. -
stat unit: More in-depth version ofstat fps:- Frame: Total time to finish each frame, similar to ms per frame
- Game: C++ or Blueprint gameplay operation
- Depict: CPU render time
- GPU: GPU render time
- RHIT: RHI thread time, should be just nether the current frame time
- DynRes: Shows the ratio of primary to secondary screen pct, separately for viewport width and height (if dynamic resolution is enabled)
-
stat unitgraph: Shows the 'stat unit of measurement' data with a real-time line graph plot. Useful for detecting hitches in otherwise smooth gameplay. -
stat scenerendering: Expert for identifying bottlenecks in the overall UE4 rendering pipeline. Examples: dynamic lights, translucency cost, draw call count, etc. -
stat gpu: Shows "live" per-pass timings. Useful for shader iteration and optimization. You may have to readyr.GPUStatsEnabled anefor this to work. Developers with UE4 source code may zoom in on specific GPU piece of work with theSCOPED_GPU_STATmacro. -
stat rhi: Shows memory counters, useful for debugging retentivity pressure scenarios. -
stat startfileandstat stopfile: Dumps all the real-fourth dimension stat data within the start/stop duration to a.ue4statsfile, which tin be opened in Unreal Frontend: https://docs.unrealengine.com/en-United states/Engine/Deployment/UnrealFrontend/index.html
GPU Visualizer
The stat commands are great for a real-time view of functioning, merely suppose yous find a GPU bottleneck in your scene and wish to dig deeper into a single-frame capture.
The ProfileGPU command allows you expand i frame'due south GPU work in the GPU Visualizer, useful for cases that require detailed info from the engine.
Some examples:
- In
stat gpunosotros see Translucency being slower thanBasePassby one ms. In GPU Visualizer, we then detect a translucent mesh that takes nearly 1ms. We can cull to remove or optimize this mesh to rest time taken for opaque and translucent draws. - In
stat gpunosotros see both Shadow Depths and Lights->ShadowedLights costing us frame time. In GPU Visualizer, we then identify an expensive dynamic low-cal source by name. Nosotros tin can cull to make this a static light.
For the GUI version, set r.ProfileGPU.ShowUI to 1 before running ProfileGPU .
For more details, check out the official documentation: https://docs.unrealengine.com/en-United states of america/Engine/Operation/GPU/index.html
We highly recommend using RGP in lieu of GPU Visualizer as your profiling workhorse for RDNA GPUs. RGP tin take the same workflow as in the above examples. With RGP, you lot get in-depth GPU functioning captures with more authentic timings and low-level ISA analysis.
FPS Chart
Useful for benchmarking over a long period of fourth dimension, getting stat unit of measurement times over the duration. Results get placed in a .csv file that tin can exist plotted in the CSVToSVG Tool: https://docs.unrealengine.com/en-US/Engine/Operation/CSVToSVG/index.html
Console command to toggle: startfpschart and stopfpschart
Optimizing in Unreal Engine four
This department presents full general advice for the optimization of your content and shaders in UE4.
Optimize your geometry
Good optimization practice means avoiding over-tessellating geometry that produces small triangles in screen space; in full general, avoid tiny triangles. This means that keeping your geometry in bank check is an important gene in coming together your performance targets. The Wireframe view mode accessible through the editor is a great first expect at the geometric complexity of objects in your scene. Note that heavy translucency can tedious down the Wireframe view manner and makes it expect more crowded and less helpful. RenderDoc also shows wireframe.
LODs in UE4 are an important tool to avoid lots of tiny triangles when meshes are viewed at a distance. Refer to the official documentation for details: https://docs.unrealengine.com/en-U.s./Engine/Content/Types/StaticMeshes/HowTo/LODs/index.html
Optimize your depict calls
UE4 calculates scene visibility to cull objects that will not appear in the final image of the frame. Nevertheless, if the post-culled scene still contains thousands of objects, then draw calls can go a performance result. Fifty-fifty if nosotros return meshes with depression polygon count, if in that location are too many describe calls, it can become the primary performance bottleneck because of the CPU side price associated with setting upwardly each draw phone call for the GPU. Both UE4 and the GPU driver practice piece of work per draw call.
Even so, reducing draw calls is a balancing act. If y'all make up one's mind to reduce draw calls by using few larger meshes instead of many small ones, you lose the culling granularity that yous become from smaller models.
Nosotros recommend using at least version 4.22 of Unreal Engine, to become the mesh drawing refactor with automobile-instancing. See the GDC 2022 presentation from Epic for more details: https://www.youtube.com/watch?five=qx1c190aGhs
UE4's Hierarchical Level of Detail (HLOD) system can replace several static meshes with a single mesh at a distance, to help reduce draw calls. Run into the official documentation for details: https://docs.unrealengine.com/en-US/Engine/HLOD/index.html
The ' stat scenerendering ' command can be used to check the draw call count for your scene.
Optimize your GPU execution
Nosotros covered one instance of optimizing GPU execution in the RGP and UE4 Example section earlier in the guide. We volition embrace another in the GPUOpen UE4 Optimization Case Written report section. This section covers some congenital-in tools and workflows to help optimize GPU execution in UE4.
Optimization viewmodes
The UE4 editor has many visualization tools to assist with debugging. The most notable of these for debugging performance would be the Optimization Viewmodes. For an overview of the different modes, please see the official documentation: https://docs.unrealengine.com/en-US/Engine/UI/LevelEditor/Viewports/ViewModes/alphabetize.html
- If your scene contains multiple lite sources with large source radius, then you lot might want to bank check Lite Complication to optimize overlapping lights.
- For scenes with static lighting, Lightmap Density would bear witness the texel resolution used during baked lighting for an Actor. If y'all have a small-scale object in the scene which takes up a small pixel surface area on the screen and that shows as red (high density), and then information technology could be optimized. Clicking on the Actor, and change Lighting->Overriden Lite Map Res to a lower value. The actual performance cost hither is in the retentiveness usage of the Lightmap and/or Shadowmap (depending on the lite type used).
- Static Shadowmaps can only be allowed 4 contributing lights per texel. Whatever excess stationary lights that overcontribute to a region can be visualized in Stationary Light Overlap. UE4 enforces this by changing backlog stationary lights to movable, mark them with a crimson cross and visualizing the overlap as a red region in Stationary Low-cal Overlap. Since movable lights are very expensive, we tin can optimize excess lights past reducing radius or turning off static shadowing in Light->Cast Shadows.
- Shader Complexity uses a static analysis of the number of shader instructions executed per pixel to make up one's mind pixel toll. Equally a supplement to this, we recommend Events->Wavefront occupancy and Overview->Most expensive events views in RGP to get a summary of where your frame time is going.
- Scenes with heavy translucency, leaf, or particle effects will render pixels with high values in Overdraw. If the average overdraw (marked by OD in the color ramp) stays at high values for most of your application then further optimization may exist required.
Optimize your screen percentage
Upscaling is a technique in which an application renders most of its frame at reduced resolution. And so, nigh the terminate of the frame, the application enlarges the rendered image to the desired output resolution. Rendering at lower resolution costs fewer shaded pixels while simultaneously reducing memory demands. This tin result in significant operation savings without introducing much take chances into your development or content pipelines. The trade-off is that rendering at a lower resolution tin can lead to less detailed final images. Various upscaling methods have been adult to minimize the reduction in quality from rendering at a lower resolution. Stock UE4 implements two dissever upscaling algorithms, one spatial and one temporal, which are both controlled by the console variable r.ScreenPercentage.
Assigning any value to this panel variable which is greater than 0.0 and less than 100.0 volition automatically configure UE4 to upscale your project. The specified value is treated every bit a percentage multiplier of target resolution. For case, if your target resolution is 2560×1440 andr.ScreenPercentage is set to 75.0, most of your frame will return at 1920×1080, but upscaling to 2560×1440 well-nigh the terminate of the frame.
UE4 Spatial Upscaling
Spatial Upscaling is the default upscaling method employed by UE4. Spatial upscalers are minimally invasive and straight expand a single image without requiring any additional information or context. In this respect, using a spatial upscaler is a lot like resizing a picture in an image editing tool. UE4'southward Spatial Upscaler has exceptional operation characteristics but its quality impact may be meaning when using lower resolutions compared to alternative upscaling solutions.
UE4 Temporal Upscaling
Temporal Upscaling is not UE4'south default method of upscaling. In social club to configure UE4 to utilize Temporal Upscaling, assign the value of 1 to the console variable r.TemporalAA.Upsampling. Temporal Upscaling in UE4 is applied equally role of the Temporal Anti-Aliasing algorithm (TAA), and every bit a issue, TAA must be enabled for Temporal Upscaling to be used. Temporal upscalers are more complex than their spatial counterparts. At a high level, Temporal upscaling typically renders every frame at a unlike sub-pixel starting time, so combines previous frames together to form an upscaled terminal paradigm.
Non but is the algorithm itself more circuitous, but motion vectors must be present and tracked across multiple frames to attain high quality results. Additionally, UE4 Temporal Upscaling cannot render as much of the frame at reduced resolutions as Spatial Upscaling can, because UE4 Temporal Upscaling must ever occur during the awarding of TAA. Therefore some post-process operations will all the same render at full resolution even when UE4 Temporal Upscaling is employed. UE4 Temporal Upscaler produces sizeable performance gains over native-resolution rendering, but its complexity may arrive more expensive than alternative upscaling solutions. However, the quality of resulting images tin can be very high.
FidelityFX Super Resolution 1.0
Researchers at AMD have developed an exciting additional option for upscaling in UE4. We call it FidelityFX Super Resolution 1.0, or FSR 1.0 for curt. FSR 1.0 uses a collection of cutting-edge algorithms with a item accent on creating high-quality edges, giving large functioning improvements compared to rendering at native resolution straight. FSR one.0 enables "applied performance" for costly return operations, such as hardware ray tracing. FSR 1.0 is a spatial upscaler, which ways it has the same minimally invasive nature and exceptional operation characteristics every bit UE4's Spatial Upscaler.
Information technology is recommended to expose quality presets for FSR 1.0 equally follows:
- Ultra Quality (77% screen pct)
- Quality (67% screen percentage)
- Balanced (59% screen percentage)
- Performance (fifty% screen percentage)
FSR 1.0 volition run on a broad variety of GPUs and is completely open source on GitHub. FSR 1.0 tin be integrated into your UE4.27.ane (or college) projection with our FSR plugin, or by applying this FSR patch (patch requires yous to be a UE-registered developer) for earlier versions. Check out FSR on GPUOpenfor more information.
GPUOpen UE4 optimization instance study
At AMD, we maintain multiple teams with the primary focus of evaluating the performance of specific game titles or game engines on AMD hardware. These teams ofttimes apply many of the methodologies presented in this certificate while evaluating UE4 products. In this department, nosotros will take a guided look into the progression of some of those efforts. Easy integrations of the results from optimizations discussed in this section (and more) are all available here.
Case Report 1: Apply one triangle for fullscreen draws
Step i – Place the optimization target
The life cycle of this optimization begins while evaluating a Radeon GPU Profiler (RGP) trace of Unreal Engine running on DX12. Before beginning any evaluation in RGP, ensure that UE4 is configured to emit RGP frame markers. This dramatically simplifies the task of navigating the sheer volume of data in RGP profiles and can be accomplished for DX12 by assigning the CVar value D3D12.EmitRgpFrameMarkers=i.
Under the OVERVIEW tab in RGP, there is a panel which presents a sorted listing of Most expensive events. In ane capture, 2 specific events – right next to each other under this sorting – stand out as an optimization candidate:

This pair stands out for a few specific reasons:
- The same Event with identical User Event information and very similar Duration happens twice back to back during the frame (Effect ID 2527 vs Event ID 2529). This suggests these two Events are closely related to each other; they may even be the exact same operation against different inputs or outputs. If this is true, any savings yielded while optimizing the outset issue could as well touch on the second… scaling our efforts by a gene of ii.
- There are 64 instances of this describe existence rendered. This suggests any savings yielded optimizing 1 such draw could also impact the other 63 instances, scaling our efforts past an boosted cistron of 64.
- Even a sub-microsecond improvement to each private describe could add upwards very quickly if scaled 128 times, so let's zoom in on this.
Step ii – Understand the optimization target
Before we begin attempting to optimize this upshot, we should pause to make sure we empathize both what it does and how information technology does it. Nosotros will reach this past inspecting the operation in Renderdoc. Before beginning whatever debugging exercise in Renderdoc, ensure that UE4 is configured to preserve shader debug information. If this information is available, Renderdoc volition provide much more context about the execution of a given event. You tin can accomplish this by assigning the CVar value r.Shaders.KeepDebugInfo=ane . If you are turning this value on for the kickoff fourth dimension, exist prepared to wait for completion of a lengthy shader compilation job the adjacent time you lot launch Unreal.
In the Most expensive events panel of RGP, right-clicking the desired event and selecting View in Outcome timing opens the EVENTS tab Consequence timing panel, and transports you directly to the targeted event.
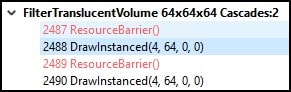
In this view, we can come across that the event is part of a debug region titled FilterTranslucentVolume, and we volition use this information to locate this result in Renderdoc moving forward.
In a Renderdoc capture of this scene, searching the Issue Browser for FilterTranslucentVolume direct transports us to the Renderdoc representation of the targeted outcome.
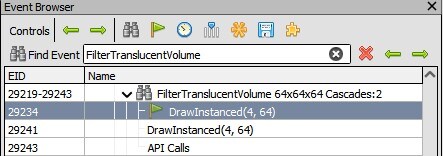
With debug information preserved, nosotros can straight meet the total HLSL source with all relevant #include south inline and all relevant #if s already evaluated for each stage of the rendering pipeline by clicking the View button at the top of the stage data panel in the Pipeline State tab. Nosotros tin likewise see the entry point in that source file for the target shader or view the raw disassembly if needed.
Inspection of the source files associated with each stage of this pipeline demonstrates that this event is reading pixels from a 64x64x64 3D texture and averaging the results into another 64x64x64 3D texture, one slice at a fourth dimension. The Pixel Shader selects an appropriate piece inside both input and output textures based on the Instance ID of the current draw. The Vertex and Geometry Shaders do no matrix manipulation against input vertices.
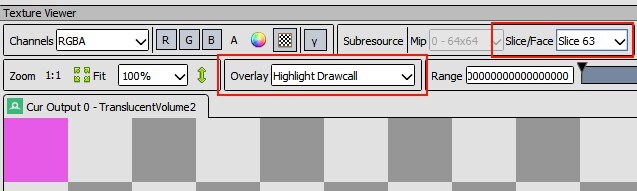
The combination of a 4 vertex Describe with a Vertex Shader that does no matrix manipulation suggests that this operation is only drawing a forepart-facing quad equally a triangle strip. The additional context of what the Pixel Shader is doing suggests that quad is probably intended to cover the unabridged 64×64 region of a single slice of the output 3D texture. Inspection of the Input Assembler stage in Renderdoc – specifically the Mesh View visualization tool – verifies these expectations for the first case drawn by this issue. The 64×64 pink region in every slice of the Highlight Drawcall overlay in the Texture Viewer tab corroborates that information for each other example, and across the entire output 3D texture space.
Step 3 – Define the optimization program
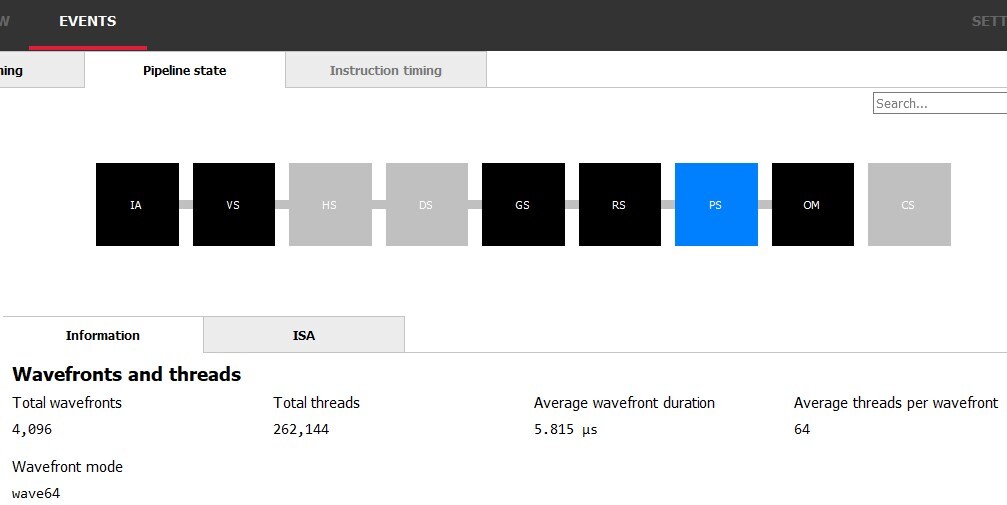
Armed with this information, we can finally begin trying to optimize! We start this process by returning to the Result timing panel in RGP. Selecting the targeted Event and so swapping to the Pipeline State tab at the meridian of the panel provides boosted information about this draw. Selecting the PS pipeline stage brings up additional information specifically about Pixel workloads.
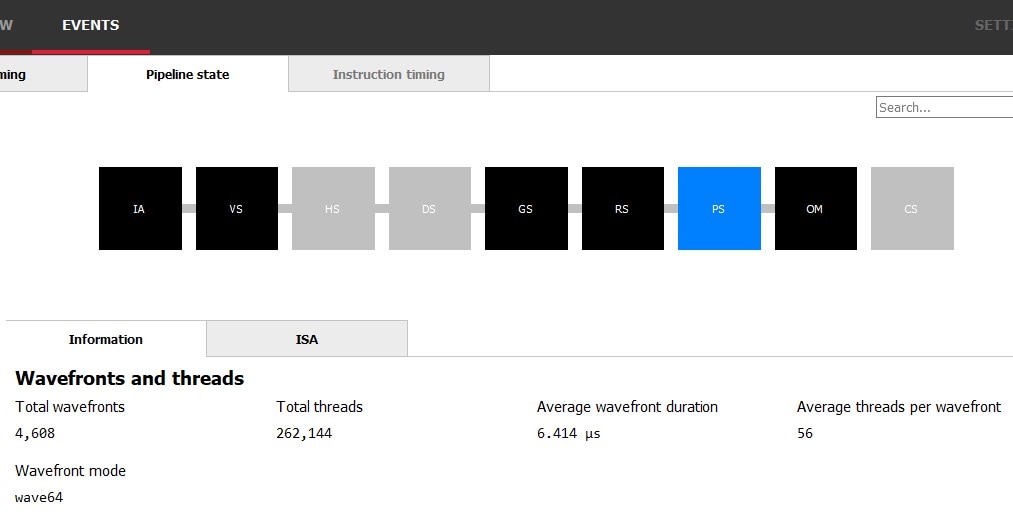
Hither we tin can see a total of 262,144 unique pixel shader invocations, which aligns with our expectations from inspecting the event in Renderdoc: every pixel in a 64x64x64 3D texture should have been output, and 64x64x64 = 262,144. The other information presented hither could be apropos. AMD GPUs organize piece of work into related groups called wavefronts. The wavefront way for this event is wave64, and so under ideal circumstances there should be 64 threads per wavefront; we only realized 56 of those threads in the average wavefront during this effect. This reality ways we may be wasting possible cycles and represents a potential opportunity for optimization. Whether that potential can be manifest depends entirely on why we're declining to realize 64 threads per wavefront.
At a loftier level, the system of related work into wavefronts normally produces highly efficient execution through SIMD. In this scenario, that organization also comes with a drawback. Considering the quad is rendered using 2 separate triangles, carve up wavefronts are generated for the pixel work associated with each of those triangles. Some of the pixels near the boundary separating those triangles terminate up beingness organized into partial wavefronts, in which some of the threads are simply disabled considering they represent pixels that are outside of the active triangle. The relatively pocket-sized dimensions of each individual 64×64 output region exacerbates this phenomenon as a pct of overall piece of work. Unabridged documents take been produced detailing causes behind this miracle. We encourage you to read some of the AMD whitepapers for additional information!
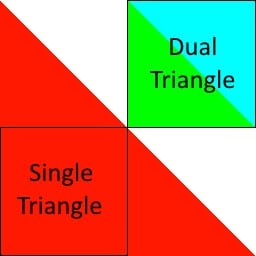
From hither, the solution to improve the efficiency of organizing existing pixel work is relatively straightforward. Since the trouble results from the beingness of a large pixel-infinite purlieus between two triangles, eliminating that boundary eliminates the trouble. While inspecting this event in Renderdoc, we learned that the entire 64×64 region represented by each slice of the render target is being output. Pixels that would fall outside that region are implicitly discarded before ever reaching the Pixel Shader phase of the rendering pipeline, and we tin have advantage of this fact to reconsider how nosotros cover this region. The image to the right shows how we could fully cover this region (so some) with a unmarried triangle. While the exact coverage afforded by the Dual Triangle representation seems more prudent at starting time, the information we've collected so far suggests that eliminating the purlieus between those ii triangles may ultimately be more efficient.
We can too theorize an additional possible benefit to this refactor. During inspection, we noted that the Pixel Shader is largely sampling pre-generated textures and averaging the results into the output return target. At that place is very piddling computational work going on here, and most of the expense for this kernel should present equally waiting on memory accesses. Eliminating the 2d triangle will modify the rasterization pattern of this quad, because individually generated wavefronts are no longer restricted to covering a single triangle – half of the input and output regions. Removing this status allows wavefronts to operate on entire blocks of compressed memory or entire scanlines of uncompressed memory in unimpeded succession. This is likely to improve the benefits yielded past spatial caching on our memory accesses, and we look we may see improvement in overall enshroud utilization every bit a result.
Footstep 4 – Implement the optimization program
With the optimization programme in place, it's time to implement. We once more employ the debug region from both RGP and Renderdoc to help united states place the advisable location to make this refactor in Unreal Engine source. Searching the source code for FilterTranslucentVolume produces a handful of results, including one which invokes the macro SCOPED_DRAW_EVENTF . That macro is producing the debug markers we see in both Renderdoc and RGP; we've plant our entry point. Inspecting the source to that part eventually takes us to the function RasterizeToVolumeTexture in the file VolumeRendering.cpp , where we observe two things:
- The telephone call to
SetStreamSource, using the vertex buffer from the objectGVolumeRasterizeVertexBuffer. We'll want to evaluate how this object gets initialized and supervene upon that initialization with the vertices for our single, larger triangle. - The call to
DrawPrimitive. When nosotros've replaced the quad equanimous of 2 triangles with a single triangle, we'll likely demand to tellDrawPrimitiveto reduce the number of primitives drawn from two to 1 besides.
With our foot now firmly in the door, the balance of this implementation do is carried out in the patch available here.
Step 5 – Brand certain the optimized implementation works
It is of import to ensure the optimization works completely and correctly before yous start measuring performance gains. Skipping this stride oftentimes results in apparent significant wins that are ultimately undercut when functional holes are later on realized. Renderdoc remains the tool of choice hither. Since we've already spent time evaluating and understanding the original implementation, knowing what to review in Renderdoc post-optimization is straightforward. We haven't touched whatever of the shaders, and then we don't wait problems there. We do need to ensure that the output of our new triangles completely covers every piece of the 3D texture, survives backface culling, and has appropriate texture coordinates. The Mesh View tool and Texture Viewer Overlays in Renderdoc make quick work of this validation.
Step 6 – Analyze performance results
The starting time and about important result to evaluate is that we run across performance savings on the event in question. This chore is easily handled past returning to the Consequence timing panel of the EVENTS tab in RGP and clicking the Show details push in the meridian correct corner of the console. This expands the details pane, which includes the overall elapsing of the individual chore. In this instance, we tin can encounter a reduction of about 20us.
Before – dual triangle quad (4 vertices)
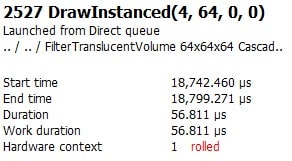
After – unmarried triangle quad (3 vertices)
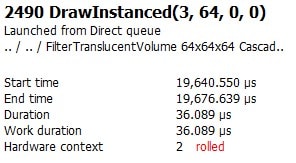
Because we previously identified that this exact consequence seems to happen twice, nosotros can likewise easily demonstrate that we see those 20us savings twice. Not bad!
There is also value in ensuring we correctly understood why things have gotten faster. Sometimes, additional savings come out of this exercise when yous realize you still oasis't fixed the issue you set out to fix. We will use both RGP and Renderdoc in this evaluation. Since we have already used RGP to encounter the inefficient thread utilization of our wavefronts, it is easy to render to that view in the Pipeline state panel of the EVENTS tab and validate the average threads per wavefront of Pixel Shader work has increased. They have – all the manner 64, and this is exactly what we wanted to meet. This indicates nosotros have successfully eliminated all fractional wavefronts from this event equally a result of this operation.
We also see a hint here that our theorized improvement to cache utilization may have borne fruit. In addition to spawning fewer and more efficiently organized wavefronts, the average wavefront duration has simultaneously decreased from vi.414us to 5.815us. However, this data is anecdotal and does not prove anything. In club to get proof that cache utilization improved, nosotros can inspect AMD-specific performance counters.
Unfortunately, as of the time of this writing RGP does not yet support streaming operation counters. However, latest versions of Renderdoc practise, including AMD-specific functioning counters! We can audit this data in a Renderdoc capture of our scene by selecting Window > Performance Counter Viewer to open the associated tab. Clicking the Capture counters button opens a dialog which includes an AMD dropdown, from which we can select enshroud hit and miss counters for all cache levels.
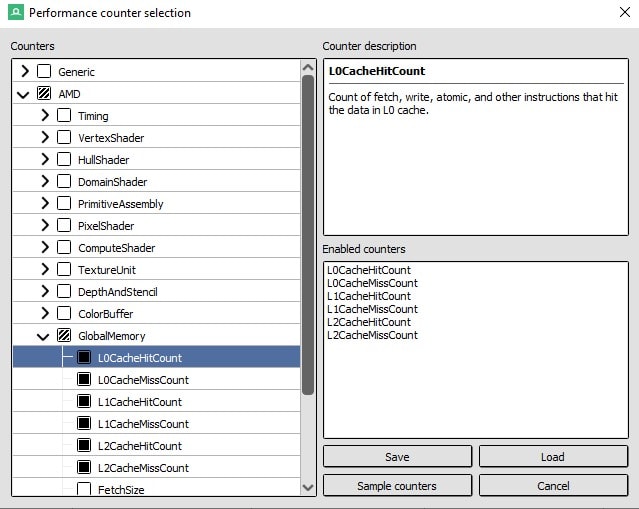
Afterwards clicking the Sample counters button, Renderdoc will re-render the scene with counters enabled. Side by side to the Capture counters button in the Performance Counter Viewer tab is a push button that says Sync Views. Ensure that Sync Views is enabled, and so select the targeted event in the Issue Browser. If you already had the targeted event selected, select a different consequence and so but go back. The Operation Counter Viewer tab will automatically scroll to and highlight the row containing counters for the targeted result.
By combining the cache striking counts and cache miss counts, nosotros can produce representations of effective cache utilization as a percentage of cache requests which were successful. That practice was completed in excel for this optimization and the raw data is presented here:
| Dual-Tri | Single-Tri | DT Hit | DT Miss | ST Hit | ST Miss | |
|---|---|---|---|---|---|---|
| L0 | 95.60% | 99.29% | 4426426 | 203518 | 3034589 | 21563 |
| L1 | 56.52% | 23.21% | 37413 | 28777 | 5092 | 16850 |
| L2 | 71.60% | 73.37% | 83457 | 33095 | 49350 | 17908 |
| Overall | 94.49% | 98.21% | 4547296 | 265390 | 3089031 | 56321 |
These results demonstrate significant overall comeback and show hugely successful L0 utilization afterward applying this optimization. This assay of performance results indicates success across all criteria.
Pace vii – Make sure nothing else is broken
Unreal Engine is a big and complex code base, and sometimes it tin be difficult to make targeted changes that don't have side effects. Testing paradigms invariably modify from projection to project and from optimization to optimization, but a few tips to go on in mind:
- Apply a debugger. Breakpoints can easily provide you with callstacks and context any fourth dimension anyone invokes lawmaking that you lot've changed. Make certain you expect it every time it happens.
- Suspension down all identified invocations in Renderdoc using the same strategies outlined in Pace 2.
- Test more than one scene, and continue in listen that if your project is dynamic… testing still images may be insufficient to catch all issues.
- Static analysis may be required depending on your use example and target audience. It's the hardest reply, but sometimes it's also the best.
- Sometimes "shut enough" is the same thing as "skillful plenty", particularly if you aren't distributing your changes externally. If your change produces artifacts to intermediate values in Renderdoc that are non noticeable in the last scene, you may non demand to fix that.
- Sometimes an optimization is non intended to produce identical results equally the original algorithm. Sometimes a slightly worse merely significantly faster reply is a good tradeoff, especially for video games.
- Computing the Mean Squared Mistake (MSE) is a valuable tool for objectively quantifying artifacts and making sound decisions about error tolerance. AMD Engineers frequently use Compressonator to aid with this kind of assay.
Executing this stride properly is e'er important and tin can sometimes increase the relative value of an optimization. While performing this exercise on the unmarried-triangle optimization discussed here, nosotros identified many draws beyond the original pair that were positively affected by this optimization. Overall expected savings increased accordingly.
Further reading
Unreal Engine
Develop for Unreal Engine on AMD hardware with our plugin, performance and characteristic patches, including FidelityFX support.

Radeon™ GPU Profiler
RGP gives you unprecedented, in-depth access to a GPU. Easily analyze graphics, async compute usage, event timing, pipeline stalls, barriers, bottlenecks, and other operation inefficiencies.



Subsurface Scattering in Unreal Forrad Renderer (2017) – YouTube link
This talk discusses how subsurface scattering is implemented in Unreal Engine's forward renderer. Considering UE4 implements subsurface scattering as a screen infinite effect, it wasn't available on the frontward path by default, then a new technique had to be implemented, and one that had to still work with the UE4 material system and editor.


Programmer Guides
Browse our developer guides, and find valuable advice on developing with AMD hardware, ray tracing, Vulkan, DirectX, UE4, and lots more than.

FEMFX
A multithreaded CPU library for deformable fabric physics, using the Finite Chemical element Method (FEM)



Developer Guides
Browse our developer guides, and discover valuable advice on developing with AMD hardware, ray tracing, Vulkan, DirectX, UE4, and lots more.

Samples Library
Scan all our useful samples. Perfect for when you're needing to get started, want to integrate one of our libraries, and much more than.
Why not detect what else GPUOpen tin can offer yous?
Source: https://gpuopen.com/unreal-engine-performance-guide/
0 Response to "ue4 draw line in 3d space"
Post a Comment